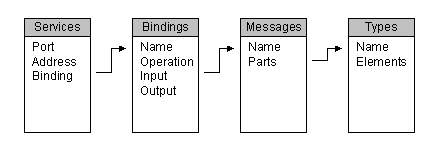
I won't go into a long description of how WSDL files are formatted, because I probably don't know enough to give you a good explanation, and there are plenty of other sites that already have that information available and ready to read (just do a Google search), and if you've even read this far in the first place you probably already know. However, I will give you a basic visual of how the WSDL sections are related:
Looks kind of like a nice little set of tables in a relational database, doesn't it? You could just write a query with a couple of outer joins and display all of the information in a nice little report. Well, there's just one problem...
XML is not a relational database!
I won't rehash that argument because it's already been made, but I will extend it to say that if we're using XML for WSDL files, we shouldn't pretend like we're using a database. We're not. We're using XML. And we should structure our data accordingly.
I understand that part of the promise of SOAP was that its complexity would be "hidden" by APIs and wrappers, so developers like me would never have to worry about looking at a WSDL file or writing a raw SOAP request. Unfortunately, because I'm a developer I don't want things to be "hidden". I want to see the technology I'm working with in all its naked glory. Sure, I'll use the APIs when they're convenient, but if I'm troubleshooting or doing something a little out of the ordinary, then I'm going to want to actually read the XML and write my own SOAP.
In its current form, WSDL is just too hard to read, unless your mind happens to be a parsing engine that makes recursive calls and stores hash tables of data elements as it goes. I know that we should all just be programmatically parsing the WSDL files anyway, but heck, have you ever tried to write a parser to do that for you? Big pain in the butt, and more complex than it first seems -- what, with all the namespaces you might have to deal with.
Here's what I'd like to see: de-normalized WSDL files. We could just have something like:
<service>
<binding>
<operation>
<input>
<message>
<part />
<part />
...
</message>
</input>
<output>
<message>
<part />
<part />
...
</message>
</output>
</operation>
<operation>
...
</operation>
</binding>
<binding>
...
</binding>
</service>
<service>
...
</service>
Now that I could follow. Yes, you might end up repeating redundant messages and parts in various similar bindings and operations and services. Yes, the WSDL files would probably be larger because of that. Yes, it would be harder to make global changes in the file.
But who cares? It would be easier to read and easier to parse, and frankly, it would probably be easier to write. Programmatically or not.
Who cares if you end up repeating information? While that might be offensive in principal to a third-normal-form-loving DBA, it makes the processing of an XML file a whole lot easier. And web services are supposed to be consumed, aren't they?
Who cares if the WSDL files are larger? Bandwidth is cheap, and the files aren't generally going to be all that big anyway. If we were really concerned with file size, the standard would have suggested that all WSDL files should be compressed and sent out as binary files (I'd better not say that too loud...someone might decide to implement that and REALLY screw up my readability problems).
Who cares if it's hard to make global changes? How often do you change your WSDL files? A couple of times a year? How many times per day do they get read? With the resulting ratio of about a million to one for reads versus writes, shouldn't we be concentrating on how to make them easier to read instead of easier to write? And besides, your WSDL files should be auto-generated anyway, so outputting redundant information shouldn't be a problem. If you're some poor sap who has to write WSDL files by hand, well I've got a great tip for you: to make a global change, open your WSDL file in a text editor and do a find-and-replace. Bang, you're done. Heck, you can even do that in Windows Notepad if you had to!
Now, I know that I'm oversimplifying a bit with regards to some of the complex data types that are floating around out there. Granted, most of them could still be flattened out, but there could be a few that have to remain nested for one strange reason or another. I'd make an exception in that case. At least then I'd only have to scroll between the <types> section and the rest of the file, which is much better than scrolling between four different sections of the file like I have to now. On the other hand, you could even get rid of that problem if you were allowed to put <part> elements within <part> elements...
So, who do I talk to about this?